Using AI in PowerShell scripts - for free and without privacy concerns!

Artificial Intelligence, namely GenAI and LLMs (large language models), is everywhere today. If you’ve managed to avoid the AI hype so far, you are either a liar🤥 or have been living under a rock🪨.
Many of you are probably already using LLMs, for example via GitHub Copilot, to help in writing scripts/code. Using GenAI makes scripting more fun and saves you a considerable amount of time, effort and googleing. But that’s not what this blog post is about.
In this article I’ll show you
- how to use LLMs in your PowerShell script and
- how to do it for free and without having to worry about data security and privacy
So let’s dive right in!
If you are not familiar with terms like GenAI and LLM, you can refer to the Glossary of GenAI Terms by the University of British Columbia.
Setting up the environment
Running LLMs locally
Running an LLM on your local machine as opposed to using cloud-based services means that:
- Privacy: You don’t have to worry about your data, everything stays on your computer.
- Cost: Running LLMs on your local machine is free.
There are multiple ways to run LLMs on your local machine. For the purposes of this article we’re going to use Ollama.
Ollama is an open-source tool/platform that allows you to run LLMs on your local machine and supports a wide range of different models including mistral, llama and deepseek-r1.
What makes Ollama especially suited for the task at hand is that it exposes a local REST API that you can use to with PowerShell 😍.
Running an LLM is very memory and compute intensive. Best performance is achieved having a compatible GPU (or better yet, multiple GPUs). You can run a model also on your CPU alone, but with a significant performance penalty. Having at least 16GB of RAM is recommended.
Also make sure your GPU drivers are up to date!
Installing Ollama
The latest version of Ollama can be downloaded from their website. The installation does not require administrative rights (it is installed under the user profile) and you can use the default settings.
But since this blog is about automating things, we’ll use winget in PowerShell to download and install Ollama:
1
winget install -e --id Ollama.Ollama
 Installing Ollama with winget is as easy as it gets. :)
Installing Ollama with winget is as easy as it gets. :)
After the installation is completed, you should see the Ollama icon in the system tray.
Selecting a language model
Next, we need to select the language model that we are going to use. For this we’ll head to the Ollama library to browse the available models.
Different models have different capabilities and have been trained on different datasets. Some are general purpose models, while others are more specialized for certain tasks.
 You can browse for language models on Ollama’s repository
You can browse for language models on Ollama’s repository
Unless you working on a serious gaming rig with a beefy GPU and lots of RAM, you are probably better off choosing one of the smaller models with 8 billion or less parameters. Running a large model without adequate hardware can be frustratingly slow.
Since I’m writing this article on my laptop with a single NVIDIA RTX A2000 GPU and 32GB of RAM, I’ll be using Phi-3.5-mini which is a lightweight model from Microsoft with only 3.8B parameters.
Let’s download the model using Ollama’s CLI:
1
ollama pull phi3.5
 You can download language models using Ollama’s CLI
You can download language models using Ollama’s CLI
Checking that everything is working
Now that we have the model downloaded, we can interact with it using a basic terminal-based chat interface by running:
1
ollama run phi3.5
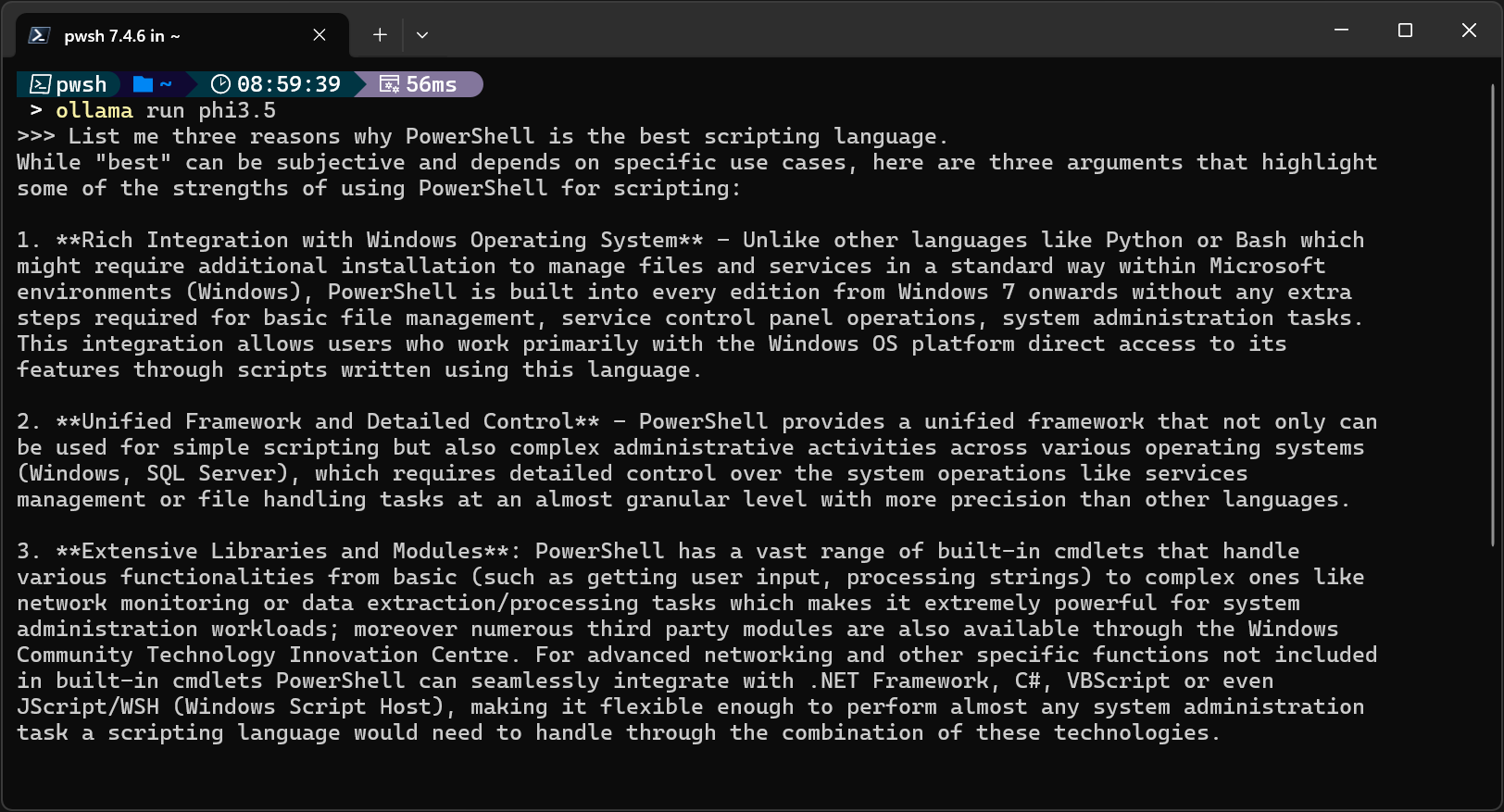 You can interact with the model using Ollama’s CLI
You can interact with the model using Ollama’s CLI
You can check if Ollama is currently using GPU by running
ollama ps. The PROCESSOR column will show the percentage of GPU/CPU usage.If you see 100% CPU, check that you have enough dedicated GPU memory available and your GPU drivers are up to date.
While this is fun and all, what we really want is to be able to use the model in a PowerShell script. Let’s see how we can do that.
Interacting with Ollama using PowerShell
Now, this where Ollama’s REST API comes in.
By default, Ollama is listening on TCP port 11434. We can verify that by using PowerShell:
1
2
3
4
5
# Make a GET request to the local Ollama API
Invoke-RestMethod -Uri 'http://localhost:11434'
# Returns:
# Ollama is running
Generating a completion
To generate a completion for a prompt (i.e. ask the model for something) we use the /api/generate endpoint:
1
2
3
4
5
6
7
POST /api/generate
{
"model": "<MODEL NAME>",
"prompt": "<YOUR PROMPT>",
"stream": false
}
Certain Ollama’s API endpoints stream responses as a series of JSON objects. When using Invoke-RestMethod, we’ll have to set
streamtofalseto get the full final response in one go since it doesn’t support streaming.
Let’s try that out with PowerShell:
1
2
3
4
5
6
7
8
9
10
11
12
# Define payload
$Payload = @{
model = "phi3.5"
prompt = "Hello World!"
stream = $false
} | ConvertTo-Json
# Set Uri
$Uri = "http://localhost:11434/api/generate"
# Make a POST request to the local Ollama API
$Response = Invoke-RestMethod -Uri $Uri -Method Post -Body $Payload -ContentType "application/json"
The response contains the actual response and some additional metadata: 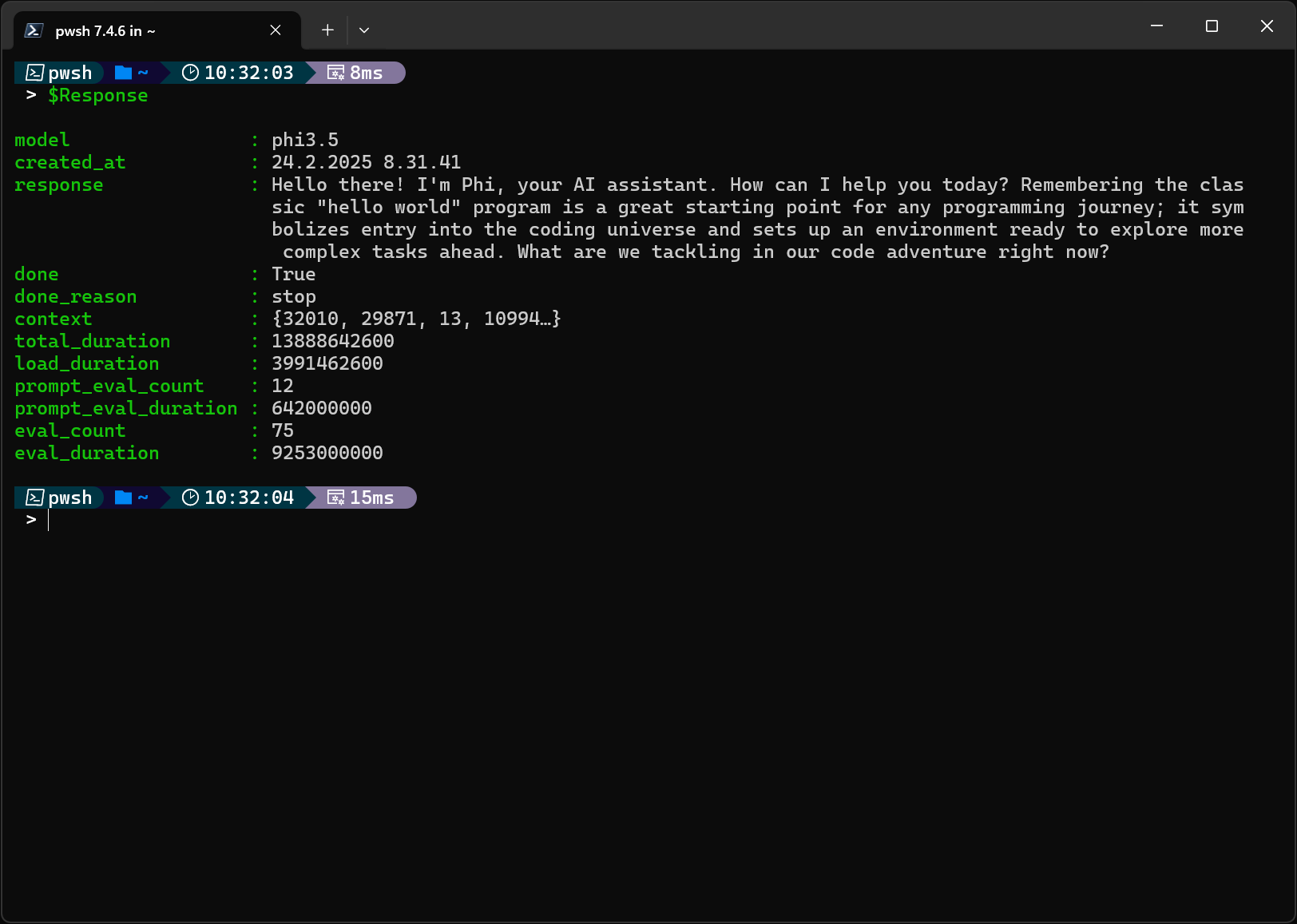 Reponse from Ollama’s API
Reponse from Ollama’s API
Streaming responses
For a better user experience, especially on devices with less-capable hardware, we can use Ollama’s streaming APIs to display the response in real-time as opposed to waiting until the full response has been generated. This way the user can see the response as it’s being generated.
Key to achieving this with PowerShell is to use .NET class System.Net.Http.HttpClient as it supports asynchronous operations. The following Invoke-StreamingOllamaCompletion function uses /api/generate endpoint to generate a completion and streams the response to the console:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
Function Invoke-StreamingOllamaCompletion {
<#
.SYNOPSIS
Invokes an asynchronous completion request to the Ollama streaming API.
.DESCRIPTION
This function sends an asynchronous HTTP POST request to the Ollama streaming API to generate a completion based on the provided model and prompt.
It reads the response stream as it comes in and outputs the response.
.PARAMETER Model
The name of the model to use for generating the completion.
.PARAMETER Prompt
The prompt to send to the model for generating the completion.
.EXAMPLE
Invoke-StreamingOllamaCompletion -Model "phi3.5" -Prompt "Tell me a joke."
.NOTES
Make sure the Ollama API is running locally on port 11434.
Author: Henri Perämäki
Contact: peramhe.github.io
#>
param (
[string]$Model,
[string]$Prompt
)
try {
# Define payload
$Payload = @{
model = $Model
prompt = $Prompt
} | ConvertTo-Json
# We need to use HttpClient for async calls
# https://learn.microsoft.com/en-us/dotnet/api/system.net.http.httpclient?view=net-9.0
$HttpClient = [System.Net.Http.HttpClient]::new()
# Prepare HTTP request
$HTTPRequest = [System.Net.Http.HttpRequestMessage]::new("Post", "http://localhost:11434/api/generate")
$HTTPRequest.Content = [System.Net.Http.StringContent]::new($Payload, [System.Text.Encoding]::UTF8, "application/json")
# Send the request async and only wait for the headers
$HTTPResponse = $HttpClient.SendAsync($HTTPRequest, "ResponseHeadersRead").Result
# Check if the request was successful
If (!$HTTPResponse.IsSuccessStatusCode) {
Throw "Error calling Ollama API. Status code: $($HTTPResponse.StatusCode) - $($HTTPResponse.ReasonPhrase)"
}
# Read the response stream as it comes in
$MemoryStream = $HTTPResponse.Content.ReadAsStreamAsync().Result
$StreamReader = [System.IO.StreamReader]::new($MemoryStream)
while (!$StreamReader.EndOfStream) {
$Line = $Response = $null
$Line = $StreamReader.ReadLine()
If ($Line) {
$Response = ($Line | ConvertFrom-Json -ErrorAction SilentlyContinue).Response
If ($Response) {
Write-Host $Response -NoNewLine
}
}
}
} catch {
Throw $_
} finally {
# Clean up
$StreamReader.Close()
$HttpClient.CancelPendingRequests()
$HttpClient.Dispose()
}
}
The function sends an asynchronous HTTP POST request to the Ollama’s streaming API and only waits for the headers. It then gets a MemoryStream from the response and reads it line by line using a StreamReader. If the line contains a JSON object, the response is extracted and outputted to the console without a newline. Try-catch-finally block is used to make sure that all resources are properly disposed of and any pending operations cancelled, even if Ctrl+C is used to stop the script.
Writing an AI-powered script
Now that we know how to interact with Ollama APIs using PowerShell, we can use that knowledge to put together a script that leverages GenAI.
As an example, I’ve created a Proof-of-Concept script called Debug-LastError.ps1 that helps in debugging the last error that occurred in the current PowerShell session.
First, let’s set the scene:
You are running a script that is meant to fetch the display names of the software installed to your computer:
1
2
3
4
5
6
7
8
9
10
$ErrorActionPreference = "Stop"
$UninstallKeys = Get-ChildItem 'HKLM:\Software\Microsoft\Windows\CurrentVersion\Uninstall\'
# Print trimmed DisplayNames
Foreach ($Key in $UninstallKeys) {
$DisplayName = $null
$DisplayName = $Key.GetValue("DisplayName")
Write-Host $DisplayName.Trim()
}
Unfortunately, the above script is not very well written and is not always working as expected. Instead of returning the full list of display names, the script suddenly stops with a somewhat generic error message about a null-valued expression🤬.
Fortunately, we can use Debug-LastError.ps1 to help us debug the error! Let’s see it in action: 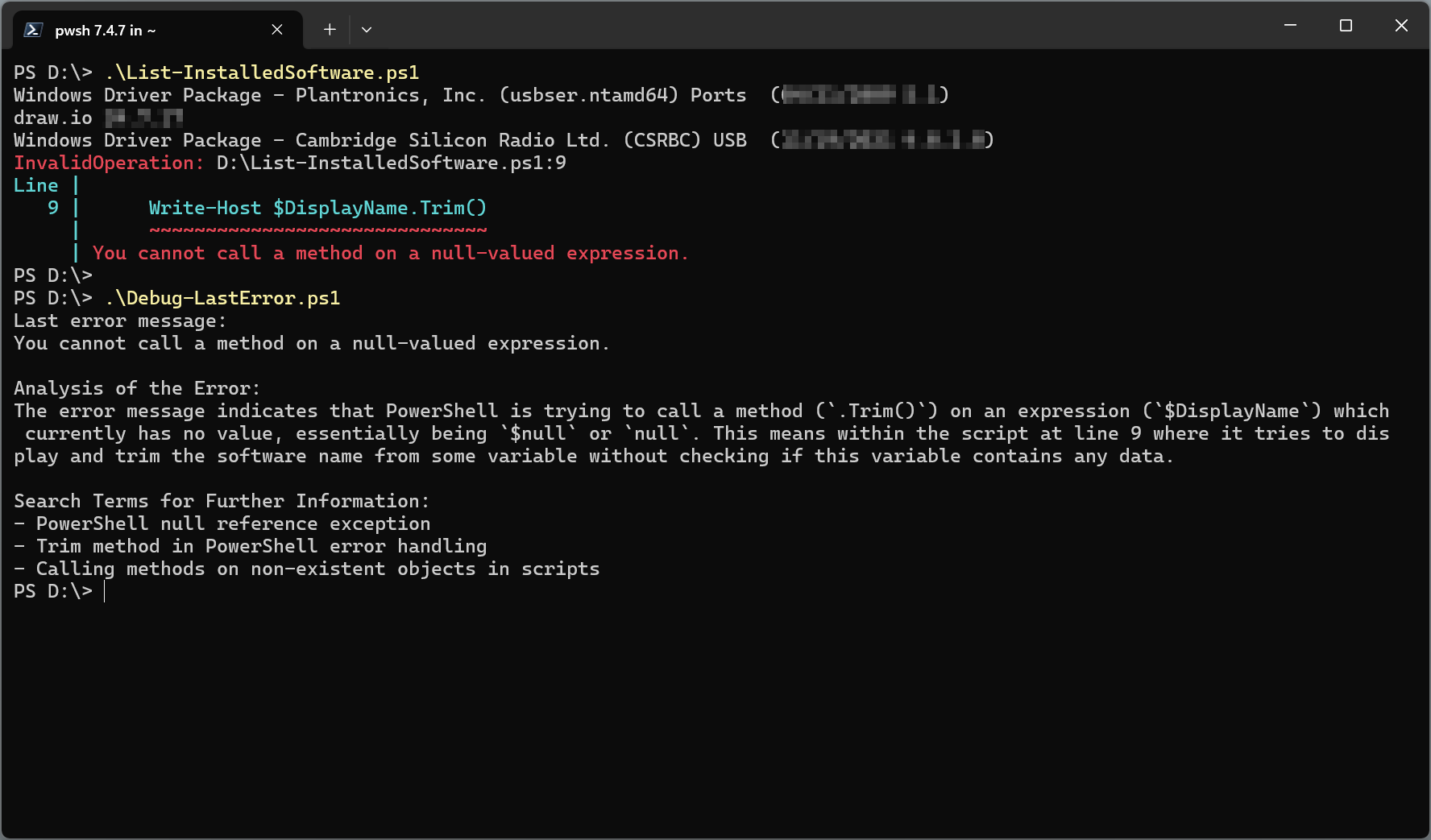 Debugging the error with Debug-LastError.ps1
Debugging the error with Debug-LastError.ps1
Debug-LastError.ps1 uses Ollama’s streaming completion API with a prompt that contain instructions for the LLM along with details of the error. If the error occurred when running a script, its source is also used as additional context. I’ve played around with it a bit and it seems to work reasonably well in many cases, although sometimes the responses can be a bit off so your mileage may vary.
As you may note from the screenshot, I had to disable my oh-my-posh to get
Debug-LastError.ps1to work properly. Oh-my-posh seem to modify the error that gets stored in$Errorand details are lost in the process.
Try it out yourself
You can download the script from my GitHub repository and try it out yourself:
peramhe.github.io-examples/Using-AI-In-PowerShell-Scripts/Debug-LastError.ps1 at main · peramhe/peramhe.github.io-examples
Please be aware that
Debug-LastError.ps1is meant as a proof of concept and might not work in all cases. It’s also worth noting that LLMs are prone to hallucinating and may provide incorrect information, which seems to especially be the case with the smaller LLMs like the one I used in this article.
Conclusion
In this article, we’ve seen how to use LLMs in PowerShell scripts using Ollama. We’ve also seen how to interact with Ollama’s REST APIs using PowerShell and how to stream responses in real-time. Lastly, I introduced a proof-of-concept script that uses GenAI to help debug errors in PowerShell scripts.
Further resources
If you want to interact with AI in PowerShell but don’t want to create the underlying implementation yourself, there are ready-to-use modules available that you can use. Check out the following: